Machine Learning [Regression] practice
Question 1.
from sklearn.datasets import load_iris
import pandas as pd
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['target'] = iris.target
df['target_name'] = iris.target_names[iris.target]
#X standardscale
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X, y = iris.data, iris.target
#X 값 표준화
X_sc = scaler.fit_transform(X)
X_test_sc = scaler.transform(X_test)
df.head()

from sklearn.model_selection import train_test_split
#train data와 타겟 분리
X_train, X_test, y_train, y_test = train_test_split(X_sc, y, test_size=0.2, random_state=42)
print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)
#result
(120, 4) (30, 4) (120,) (30,)
import seaborn as sns
sns.pairplot(df, vars=['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)'], hue='target_name')

len(df)
#result
150
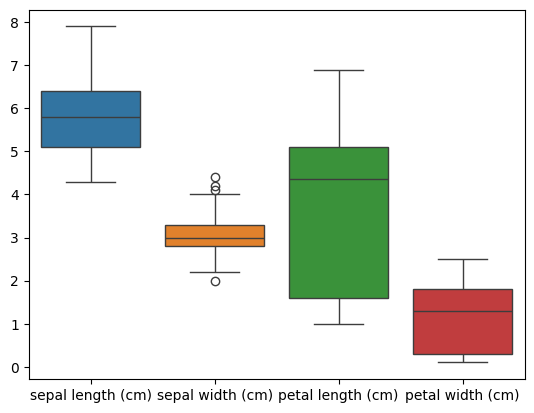
sns.boxplot(data=df[['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']])
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 150 entries, 0 to 149
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 sepal length (cm) 150 non-null float64
1 sepal width (cm) 150 non-null float64
2 petal length (cm) 150 non-null float64
3 petal width (cm) 150 non-null float64
4 target 150 non-null int64
5 target_name 150 non-null object
dtypes: float64(4), int64(1), object(1)
memory usage: 7.2+ KB
from sklearn.linear_model import LogisticRegression
model_lor = LogisticRegression()
model_lor.fit(X_train, y_train)
LogisticRegression
LogisticRegression()
def get_att(x, feature_names):
print('클래스 종류:', x.classes_)
print('독립변수 갯수:', x.coef_.shape[1])
print('들어간 독립변수(x)의 이름:', feature_names)
print('가중치:', x.coef_)
print('바이어스:', x.intercept_)
get_att(model_lor, df.columns[:-2]) # df의 마지막 열은 타겟 변수이므로 제외한 나머지 열을 독립변수의 이름으로 사용합니다.
#result
클래스 종류: [0 1 2]
독립변수 갯수: 4
들어간 독립변수(x)의 이름: Index(['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)',
'petal width (cm)'],
dtype='object')
가중치: [[-1.0205085 1.13224015 -1.81712983 -1.68691733]
[ 0.53384517 -0.2826248 -0.34271392 -0.73094819]
[ 0.48666333 -0.84961535 2.15984376 2.41786552]]
바이어스: [-0.24838294 1.97381496 -1.72543202]
from sklearn.metrics import accuracy_score
# 모델을 사용하여 테스트 데이터에 대한 예측값을 생성합니다.
y_pred = model_lor.predict(X_test)
# 예측값과 실제 타겟값을 비교하여 정확도를 계산합니다.
accuracy = accuracy_score(y_test, y_pred)
# 정확도를 출력합니다.
print("Accuracy:", accuracy)
#result
Accuracy: 1.0
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
# Train 데이터의 예측값과 실제 타겟값을 3차원 산점도로 그립니다.
fig = plt.figure(figsize=(12, 6))
ax1 = fig.add_subplot(121, projection='3d')
ax1.scatter(X_train[:, 0], X_train[:, 1], X_train[:, 2], c=y_train, cmap='viridis', label='Train Data')
ax1.set_xlabel('Feature 1')
ax1.set_ylabel('Feature 2')
ax1.set_zlabel('Feature 3')
ax1.set_title('Train Data')
# Test 데이터의 예측값과 실제 타겟값을 3차원 산점도로 그립니다.
ax2 = fig.add_subplot(122, projection='3d')
ax2.scatter(X_test[:, 0], X_test[:, 1], X_test[:, 2], c=y_pred, cmap='viridis', marker='^', label='Test Predictions')
ax2.set_xlabel('Feature 1')
ax2.set_ylabel('Feature 2')
ax2.set_zlabel('Feature 3')
ax2.set_title('Test Predictions')
plt.show()

Question 3.
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeRegressor
from sklearn.metrics import mean_squared_error
# 3. 모델 학습
model = DecisionTreeRegressor(max_depth=5, random_state=42)
model.fit(X_train, y_train)
#result
DecisionTreeRegressor
DecisionTreeRegressor(max_depth=5, random_state=42)
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
print("MSE:", mse)
#result
MSE: 0.0
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeRegressor
from sklearn.metrics import mean_squared_error
시각화
plt.figure(figsize=(10, 6))
plt.scatter(y_test, y_pred, alpha=0.5)
plt.plot([min(y_test), max(y_test)], [min(y_test), max(y_test)], color='red') # 대각선
plt.xlabel('Actual Values')
plt.ylabel('Predicted Values')
plt.title('Actual vs Predicted Values')
plt.show()

Question 5.
from sklearn.datasets import load_iris
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
# KMeans 클러스터링
kmeans = KMeans(n_clusters=3, n_init=10, random_state=42)
clusters = kmeans.fit_predict(X_train)
# 클러스터링 결과를 train 데이터프레임에 추가
df_train = pd.DataFrame(X_train, columns=iris.feature_names)
df_train['target'] = y_train
df_train['cluster'] = clusters
print(df_train.head())
sepal length (cm) sepal width (cm) petal length (cm) petal width (cm) \
0 -1.506521 1.249201 -1.567576 -1.315444
1 -0.173674 3.090775 -1.283389 -1.052180
2 1.038005 0.098217 0.364896 0.264142
3 -1.264185 0.788808 -1.226552 -1.315444
4 -1.748856 0.328414 -1.397064 -1.315444
target cluster
0 0 0
1 0 0
2 1 1
3 0 0
4 0 0
import matplotlib.pyplot as plt
import seaborn as sns
# 클러스터링 결과 시각화 (train 데이터)
plt.figure(figsize=(12, 6))
# subplot 1: 클러스터 레이블
plt.subplot(1, 2, 1)
sns.scatterplot(data=df_train, x='sepal length (cm)', y='sepal width (cm)',
hue='cluster', palette='viridis', style='cluster', s=100)
plt.title('KMeans Clustering Results')
plt.xlabel('Sepal Length (cm)')
plt.ylabel('Sepal Width (cm)')
plt.legend(title='Cluster')
# subplot 2: 실제 타겟 레이블
plt.subplot(1, 2, 2)
sns.scatterplot(data=df_train, x='sepal length (cm)', y='sepal width (cm)',
hue='target', palette='viridis', style='target', s=100)
plt.title('Actual Target Labels')
plt.xlabel('Sepal Length (cm)')
plt.ylabel('Sepal Width (cm)')
plt.legend(title='Target')
plt.tight_layout()
plt.show()

import numpy as np
from sklearn.metrics import accuracy_score
from scipy.stats import mode
# 각 클러스터에 대한 가장 빈번한 실제 타겟 레이블을 찾기
labels = np.zeros_like(clusters)
for i in range(3):
mask = (clusters == i)
labels[mask] = mode(y_train[mask])[0]
# 정확도 계산
accuracy = accuracy_score(y_train, labels)
print(f'Clustering Accuracy: {accuracy:.2f}')
#result
Clustering Accuracy: 0.80
Question 2.
X = np.load("/content/sample_data/cal_X.npy")
y = np.load("/content/sample_data/cal_y.npy")
X
array([[ 8.3252 , 41. , 6.98412698, ..., 2.55555556,
37.88 , -122.23 ],
[ 8.3014 , 21. , 6.23813708, ..., 2.10984183,
37.86 , -122.22 ],
[ 7.2574 , 52. , 8.28813559, ..., 2.80225989,
37.85 , -122.24 ],
...,
[ 1.7 , 17. , 5.20554273, ..., 2.3256351 ,
39.43 , -121.22 ],
[ 1.8672 , 18. , 5.32951289, ..., 2.12320917,
39.43 , -121.32 ],
[ 2.3886 , 16. , 5.25471698, ..., 2.61698113,
39.37 , -121.24 ]])
y
array([4.526, 3.585, 3.521, ..., 0.923, 0.847, 0.894])
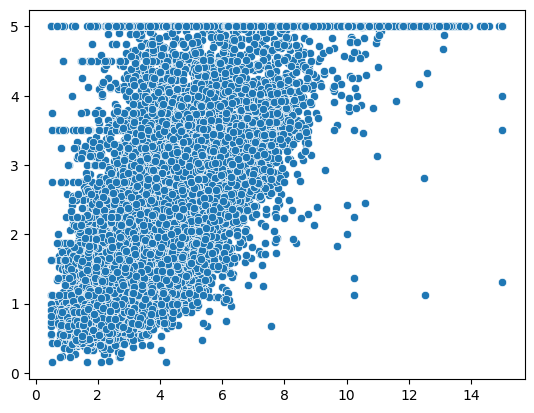
sns.scatterplot(x=X[:, 0], y=y)
# train과 test 데이터로 분리 (8:2 비율)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
from sklearn.linear_model import LinearRegression
house_model = LinearRegression()
house_model.fit(X_train, y_train)
LinearRegression
LinearRegression()
from sklearn.metrics import mean_squared_error
y_pred = house_model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
print(f"MSE: {mse}")
#result
MSE: 0.5558915986952422
Question 4.
url = "https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv"
titanic = pd.read_csv(url)
titanic.head()

def Sex_en(x):
if x == 'male':
return 0
else:
return 1
titanic['Sex_en'] = titanic['Sex'].apply(Sex_en)
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# 필요한 특성 선택
features = ['Pclass', 'Sex_en', 'Age', 'SibSp', 'Parch', 'Fare']
# 입력 변수 X와 타겟 변수 y 설정
X = titanic[features]
y = titanic['Survived']
X_train, X_test, y_train, y_test = train_test_split(X, y ,test_size=0.2, random_state=42)
titanic['Age'] = titanic['Age'].fillna(titanic['Age'].mean())
titanic.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 13 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 891 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
12 Sex_en 891 non-null int64
dtypes: float64(2), int64(6), object(5)
memory usage: 90.6+ KB
rf_classifier = RandomForestClassifier()
rf_classifier.fit(X_train, y_train)
RandomForestClassifier
RandomForestClassifier()
from sklearn.metrics import f1_score
y_pred = rf_classifier.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
f1_score = f1_score(y_test, y_pred)
print("Accuracy:", accuracy)
print("f1_score:", f1_score)
#result
Accuracy: 0.8044692737430168
f1_score: 0.7552447552447553'Study Note > Python' 카테고리의 다른 글
| Machine Learning [scikit-learn] practice (0) | 2024.06.04 |
|---|---|
| pygwalker (0) | 2024.05.30 |
| Interactive Graphs with Altair (0) | 2024.05.30 |
| Multiple graphs (0) | 2024.05.30 |
| Dual-axis graph and Pyramid graph (0) | 2024.05.30 |



