
Normalization
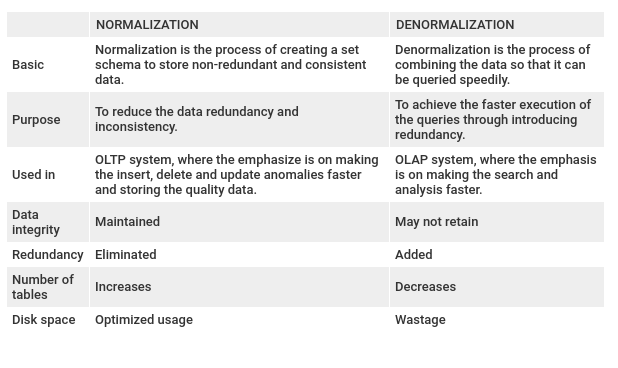
Normalization in data analysis refers to the process of organizing a database efficiently to reduce redundancy and improve data integrity and efficiency.
The three stages of normalization—first normal form (1NF), second normal form (2NF), and third normal form (3NF)—each address specific types of data redundancy and dependencies.
1. First Normal Form (1NF):
Ensures that each column (attribute) contains only atomic values, eliminating any repeating groups of data. This step establishes the atomicity of each column.
2. Second Normal Form (2NF):
Removes partial dependencies by ensuring that every non-key attribute is fully functionally dependent on the entire primary key. This step reduces redundancy and ensures consistency in the database.
3. Third Normal Form (3NF):
Eliminates transitive dependencies by ensuring that no non-key attribute is dependent on another non-key attribute. This further reduces redundancy and helps prevent update anomalies in the database.
By following these normalization steps, databases can be structured optimally to maintain data consistency, integrity, and efficiency.
Denormalization
Denormalization is the process of intentionally adding redundancy to a database schema to improve performance or simplify data retrieval.
While normalization aims to reduce redundancy and ensure data integrity, denormalization relaxes these rules to achieve specific performance goals, especially in read-heavy systems.
In denormalization, redundant data is introduced into the database design, typically by duplicating information from related tables or by combining multiple tables into one. This redundancy can speed up query processing by reducing the need for complex joins and by storing precomputed or aggregated data.
Denormalization is commonly used in scenarios where read performance is critical and where the overhead of complex joins outweighs the benefits of normalized data. However, it comes with trade-offs, such as increased storage requirements, potential data inconsistency if updates are not properly managed, and the need for careful maintenance to ensure that redundant data remains synchronized.
Overall, denormalization is a deliberate strategy used in database design to optimize read performance at the expense of some degree of redundancy and potential complexity in data management. It's often employed judiciously in situations where performance requirements warrant such trade-offs.
'Study Note > SQL Developer license' 카테고리의 다른 글
| DML, TCL, DDL, DLC (0) | 2024.05.07 |
|---|---|
| Transaction (0) | 2024.04.22 |
| Waterfall Model & Agile Model (0) | 2024.04.17 |
| Importance of data modeling (0) | 2024.04.17 |
| Modeling (0) | 2024.04.09 |

