Pivot
Pivot is commonly used in Excel, and I've learned that it can also be applied in SQL.
Through the following example, I was able to create the result values in a pivot table format.
select restaurant_name,
max(if(hh='15', cnt_order, 0)) "15",
max(if(hh='16', cnt_order, 0)) "16",
max(if(hh='17', cnt_order, 0)) "17",
max(if(hh='18', cnt_order, 0)) "18",
max(if(hh='19', cnt_order, 0)) "19",
max(if(hh='20', cnt_order, 0)) "20"
from
(
select a.restaurant_name,
substring(b.time, 1, 2) hh,
count(1) cnt_order
from food_orders a inner join payments b on a.order_id=b.order_id
where substring(b.time, 1, 2) between 15 and 20
group by 1, 2
) a
group by 1
order by 7 desc

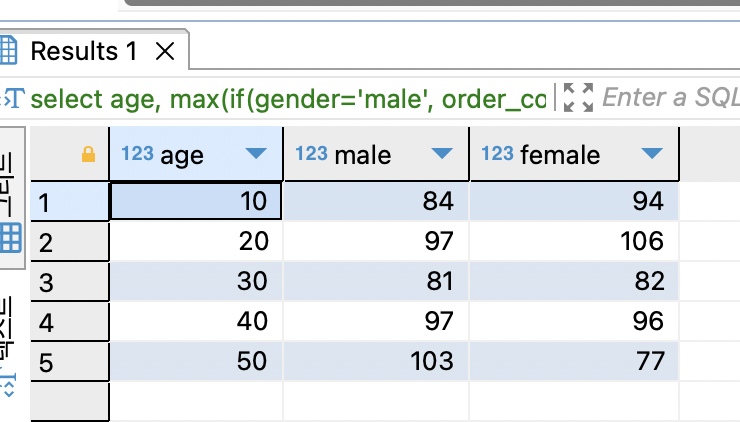
This is another practice for the Pivot table, I am still quite confused why do I need to use Max and count(1).
1. **Reason for using max**:
- In this query, the max function is used to determine the number of orders by gender. We need to select the maximum order count among males and females. By using the max function, we can choose the highest order count for each gender group.
2. **Reason for using count(1)**:
- In this query, the count(1) function is used to aggregate the number of orders for each age range. The count function is used to count the number of rows, and here it is utilized to calculate the number of orders for each age range. Count(1) does not actually count all the rows; instead, it counts 1 for each row, providing performance benefits.
select age,
max(if(gender='male', order_count, 0)) male,
max(if(gender='female', order_count, 0)) female
from
(
select b.gender,
case when age between 10 and 19 then 10
when age between 20 and 29 then 20
when age between 30 and 39 then 30
when age between 40 and 49 then 40
when age between 50 and 59 then 50 end age,
count(1) order_count
from food_orders a inner join customers b on a.customer_id=b.customer_id
where b.age between 10 and 59
group by 1, 2
) t
group by 1
order by age
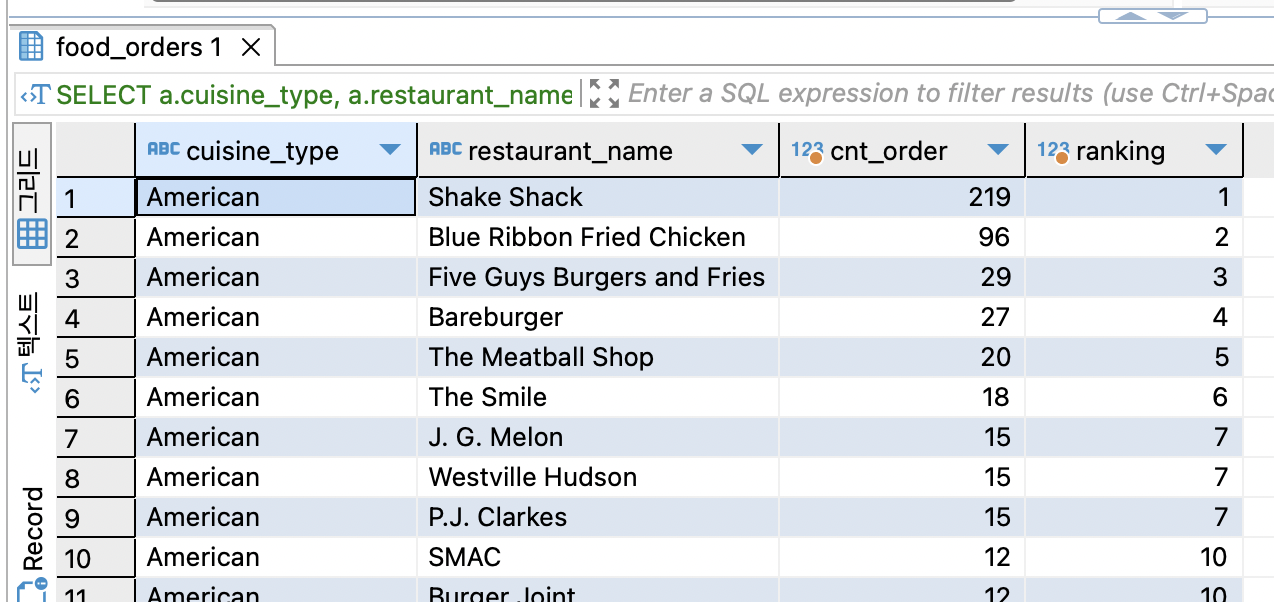
Window function
Rank () Over()
Using window functions, I was able to determine the rank by category. The rank function is always paired with "over", and it seems like it will require a lot of practice.
SELECT a.cuisine_type,
a.restaurant_name,
a.cnt_order,
rank() over (partition by cuisine_type order by cnt_order desc) ranking
FROM
(
SELECT cuisine_type,
restaurant_name,
count(1) 'cnt_order'
FROM food_orders f
group by 1, 2
) a
Sum () Over()
You can calculate the sum and cumulative sum of a desired partition using the sum() over() function.
SELECT cuisine_type,
restaurant_name,
cnt_order,
sum(cnt_order) over(partition by cuisine_type) sum_cuisine,
sum(cnt_order) over(partition by cuisine_type order by cnt_order) cum_cuisine
FROM
(
select cuisine_type,
restaurant_name,
count(1) Cnt_order
from food_orders f
group by 1, 2
) a
order by cuisine_type, cnt_order

Date
The `DATE()` function in SQL is commonly used to extract or convert date values. Its behavior may vary depending on the database system.
1. **Extracting date values with DATE() function**: It's typically used to extract the date part or convert a datetime value into a date. For example:
SELECT DATE('2024-03-23 15:30:45');
This query extracts the date part from '2024-03-23 15:30:45' and returns '2024-03-23'.
2. **Converting date values with DATE() function**: It can also be used to convert date values in different formats into a standard date format. For example:
SELECT DATE('20240323');
This query converts '20240323' into '2024-03-23'.
Practice
SELECT date(date) Changed_date,
date_format (date, '%Y') 'year',
date_format (date, '%M') 'Month',
count(*) Cnt_order
from food_orders f inner join payments p on f.order_id=p.order_id
where date_format (date, '%M')="march"
group by 2, 3
order by 2

'Study Note > SQL' 카테고리의 다른 글
| How to add localhost at DBeaver (MY SQL) (0) | 2024.04.16 |
|---|---|
| Having (0) | 2024.04.11 |
| NULL value (0) | 2024.03.22 |
| Left Join & Inner Join (0) | 2024.03.21 |
| Subquery (0) | 2024.03.21 |



